我使用香橙派5 plus刷入openwrt作为软路由使用,官方文档中说明openwrt镜像目前适配的PCIe无线网卡型号有限,并且仅支持2.4G频段wifi,而我只有一个不受支持的RTL8852BE网卡。 某一天我灵光一闪,忽然想到可以外接一个USB无线网卡来提供wifi,理论上只需要安装相应的驱动即可。我刚好有一个闲置的COMFAST 1300M…
DeepSeek 最新论文 《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》 代码解读 仓库连接如下:deepseek-ai/Engram GitHubdeepseek-ai/Engram DeepSeek 新作…
overleaf提供了开源的社区版本供用户本地部署,可以不受官方在线版本的编译时长限制,overleaf提供了一组toolkit来简化本地部署的流程,下面我们从先决条件出发,介绍在Linux服务器和Windows系统部署的流程。 常见问题和解决方案附在文章末尾 Windows部署的先决条件 Docker Desktop(依赖于WSL2环境,安装后可…
这篇文章受密码保护,输入密码才能阅读
串流是通过显卡捕获显示器画面并将其压缩作为视频流进行网络传输实现远程控制的技术,相比与其他远程控制方式,串流可以拥有更高的画面质量和帧率,是远程游戏的不二选择。 NVIDIA Experience和AMD Link都提供了对串流的支持,但目前两家的串流工具都已停止维护,目前比较主流的方案是sunshine+moonlight,其中sunshine作…
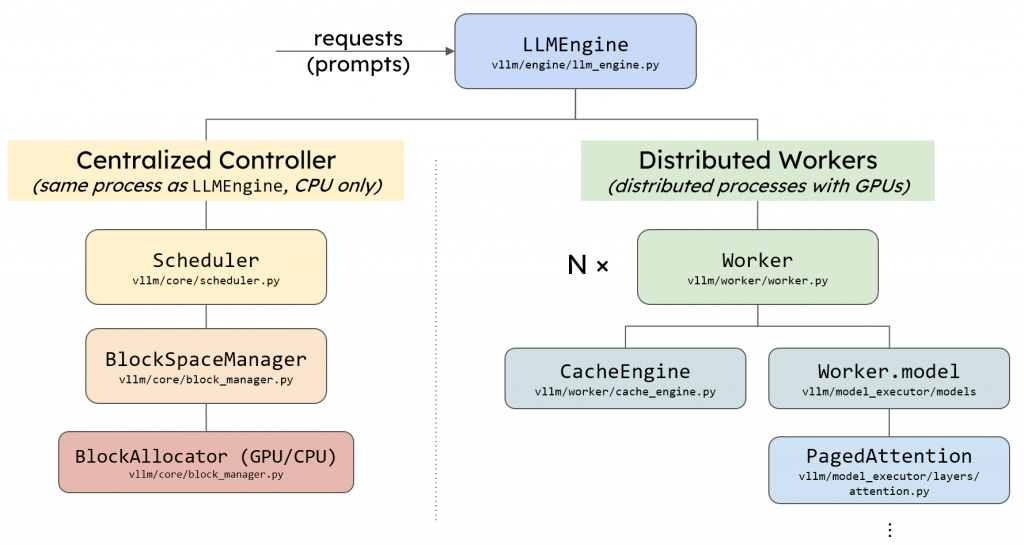
vllm中的llm_engine主要由两个模块构成,Scheduler和Executor,其中Executor负责管理并行推理时的多个设备、模型的推理计算和KV Cache的显存分配和管理,而Scheduler负责请求的调度。接下来,我将详细介绍vllm的Scheduler模块和其调度策略。 vllm模块架构 前置知识 llm是自回归的模型,在一个…
前言 最近打算基于Pytorch和vllm框架对一些底层模块进行定制,工欲善其事必先利其器,为了能够使用VSCode在远程服务器上丝滑地进行CUDA编程,环境搭建必不可少。 CMake为我们提供了一套完整的构建系统,只需要通过简单地配置文件就可以自由且自动地帮我们编译好模块和可执行文件,同时vscode的插件也对CMake提供了非常丰富的支持。CM…
前言 我在今年五月份购入了小米WR30U路由器 联通定制版,最初目的是为了刷openwrt以便在实验室使用dogcom来登陆校园网实现自动登录和多设备共享,同时也将代理功能交给路由器来做。但是后来发现这款路由器256MB的内存太捉襟见肘了,启动open clash后内存几乎占满,并且启动过程中CPU占用率会达到100%,运行非常卡顿。 之后我在香橙…
随着深度学习的层数越来越多,模型的参数也呈现出了快速增长的趋势,然而GPU内存的增长速度却远慢于模型体积的增长。有限的GPU内存限制了我们训练和部署模型的灵活性,GPU内存墙成为了现在亟待解决的问题。先前已经有许多研究进行了探索,可以概括为两大类:一是基于多级存储构建透明的数据分页和迁移机制,利用page fault在多级存储中交换数据,并对上层应…
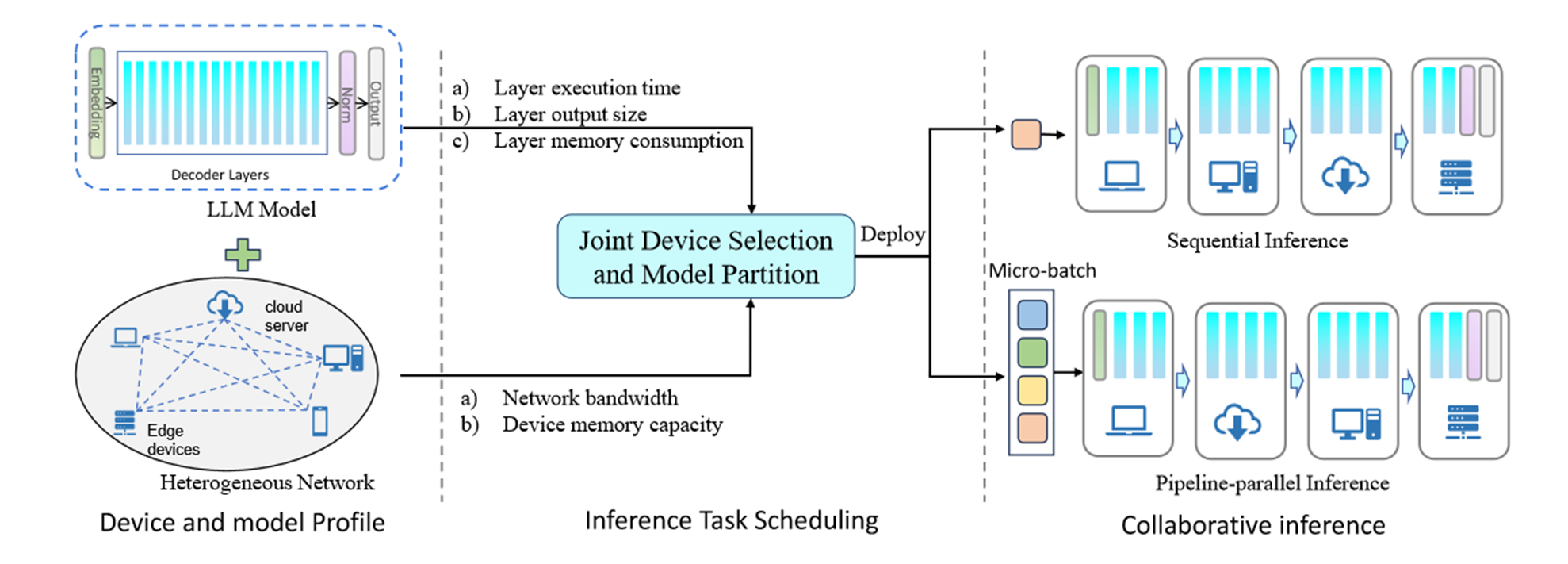
边缘计算有望通过在更靠近数据源的边缘设备上部署LLM来解决这些问题。一些工作试图利用模型量化来减小模型大小以适应资源约束的边缘设备,但这会导致精度损失。其他作品使用云边缘协作,遭受网络连接不稳定的困扰。在这项工作中,我们利用协作边缘计算来促进边缘设备和云服务器之间的协作,以共同执行高效的LLM推理。我们提出了一个通用框架,将LLM模型划分为分片并部署在分布式设备上。