不同图采样模式的区别
minibatch SGD是在GPU内存优先的前提下将GNN训练扩展到更大规模数据集上的有效训练方式,然而对于每个minibatch中的目标节点,如果使用它的全部K阶邻居节点的聚合特征来生成该节点的嵌入表示,那么minibatch子图中节点的数量会随着K的增大而急剧增加,导致GPU内存无法容纳一个子图的特征数据,这就是GNN训练中的邻域爆炸问题。
解决该问题一个简单的方法就是进行采样,只随机选取目标节点K阶邻居内的一部分节点,并且可以从不同方面去限制采样节点的数量,这实际上为每个minibatch的采样子图限制了节点数量的上限,同时可以获得很好的训练效果。
目前,主要衍生出了三种不同类别的采样算法,分别是逐节点采样、逐层采样和子图采样。
在了解不同采样算法的区别前,需要掌握统计学中偏差和方差的概念,简单来说偏差衡量参数估计量的期望值与参数真实值的偏差,若偏差为零,我们说该估计量是无偏的,即$ E_\theta(\hat \theta)=\theta $;方差则是随机变量离散程度的度量,方差越大,说明变量波动越大,越不稳定。
node wise sampling
从目标节点的邻居中选取若干节点作为源节点,若进行多层采样,那么上一层中的源节点作为下一层的目标节点继续采样。在聚合阶段,由外向内逐层聚合。此方法由GraphSAGE提出,也是目前应用最普遍的一种采样算法,在DGL和PyG中都提供了对应实现。
其缺点在于没有考虑采样的偏差和方差,随机采样也会带来一些噪声,并且采样子图中节点数虽采样层数增大呈指数增长。但节点采样简单直观、易于实现,适用于各种各样的数据集。
layer wise sampling
对目标节点的每一层都采样固定数量的邻居,这样采样子图节点数虽采样层数增加呈线性增长,同时考虑了采样带来的偏差和方差,尽量确保采样结果无偏有效。
但是逐层采样到的子图非常稀疏,不利于高效的消息传递,模型表现较差。
适用于具有明显层次结构的图数据。
subgraph wise sampling
在对图进行了划分的前提下,对每个 minibatch 随机采样一个子图,在该子图上训练完全的 GNN 模型,代表模型时 Cluster-GCN 和 GraphSAINT。
讨论
不同的采样算法适用于不同的场景,在影响模型训练效果的同时也影响计算效率和性能。我们可以认为不同的采样策略首先是针对模型本身的优化,然后我们才需要针对采样算法去从 GNN System 层面加速训练过程。
二分图与 DGL 中的 Block
二分图(Bipartite Graph),又称二部图或二分图,是图论中的一个重要概念。它是一种特殊的图,其中的节点可以被划分成两个不相交的集合,使得同一个集合内的节点之间没有边相连。

在 DGL 中,进行基于采样的 minibatch SGD 训练时,使用二分图来维护每一层采样子图中的目标节点和源节点,其数据结构名为 DGLBlock,定义在 heterograph.py 中。实际上 DGLBlock 只是简单地继承了 DGLGraph 并重写了__repo__方法而已,srcnodes 和 dstnodes 等属性方法均在 DGLGraph 中定义。
反向加权 PageRank 算法
该算法出自论文《Graph Neural Network Training with Data Tiering》,论文中讨论了应该使用什么指标来衡量节点被访问的可能性(或者说重要性),并给出了三种思路。
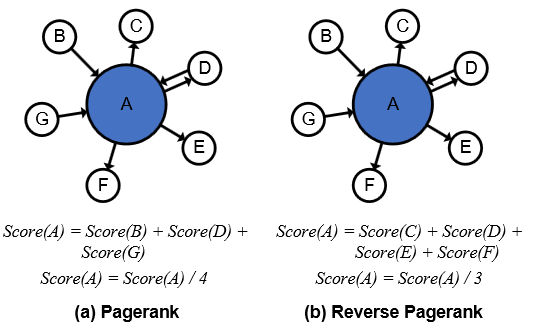
第一种指标是度,显然一个节点的度越大,其邻居节点越多,该节点被采样的概率就越大;第二种指标是反向 PageRank 算法,通过不断地迭代,使每个节点的得分都能考虑全图的节点;第三种指标是加权的反向 PageRank 算法,动机在原文中描述如下:
The third option is to further incorporate the labeling status of the nodes into the reverse pagerank method. As we explained in Section 2.1, the goal of GNN training is to create a model which can predict the labels for the unlabeled nodes. To train such models, we must be able to compare the predicted labels with the ground-truth labels. Therefore, during training, the nodes which we can pick to start the neighbor sampling are reduced to the nodes that come with with labels. This means that, if we can devise a method to statistically put further emphasis to those nodes and their surrounding nodes, we can compress the search space.
文中提到 GNN 训练的目标是使用一堆有标签的样本训练的模型来预测无标签的样本的标签,因此,我们在训练时,总是选择那些带有标签的节点作为起始目标节点,那就意味着采样是以这些节点为中心出发的,图中某个节点被采样的概率是与训练节点(也就是作者所谓的有标签的节点,这里的说法有一定迷惑性,事实上我们常用的图数据集中每个节点都拥有自己的标签,但是我们会主动将数据集划分为训练集、测试集和验证集,在训练过程中计算损失函数时,我们也只是利用到了训练集节点的标签,在推理阶段我们使用模型来预测测试集或验证集的标签,这里可以视作测试集和验证集是没有标签的)在图的分布有关联的。那么我们在选择被缓存节点的时候,就应该加大训练节点及其周围节点的权重。
这种说法从 GNN 节点分类任务的类型来看就很容易理解了,节点分类任务是一种半监督学习,也就是用少数有标签的样本去预测未知的、无标签的数据,只不过作者没有从实际的模型训练和实际的数据集的角度出发去阐释该算法的思想,但其算法思想是正确的、有效的。

上图中算法流程解释如下:
- 2-3 行得到 图中总节点数
num_node和训练节点数num_train - 4-7 行的循环中初始化每个节点的分数,统计节点入度
- 8-11 行的循环中为训练节点按照权重重新计算分数
- 12-20 行与反向 PageRank 算法相同
Minibatch 和 Subgraph 的生成
minibatch 是训练集的一个子集,其大小由 batch_size 指定,在 torch 中,由 DataLoader 负责产生 minibatch。
对 minibatch 采样后得到 subgraph,可以由一个采样器来完成,在 DGL 和 PyG 中提供了 dataloader 和 sampler 的集成接口,如 PyG 中的 NeighborLoader,同时负责生产 minibatch 和 subgraph
PaGraph 中为什么缓存出度大的节点
在 DGL 中所有的图都会被表示为有向图,对于无向图,则需要添加反方向的边,其入度等于出度。
PaGraph 中描述此问题的原文如下:
This says that with a higher out-degree, a vertex is more likely to be an in-neighbor of other vertices, and thus is more likely to be sampled in a mini-batch. Thus, it is sufficient to select high out-degree vertices for filling up the cache.
PaGraph 中说高出度的节点更可能成为其他节点的 in-neighbor,也就是入邻居,了解入邻居和出邻居的概念后,这个策略就很好理解了,缓存策略永远与采样策略是紧密联系在一起的。
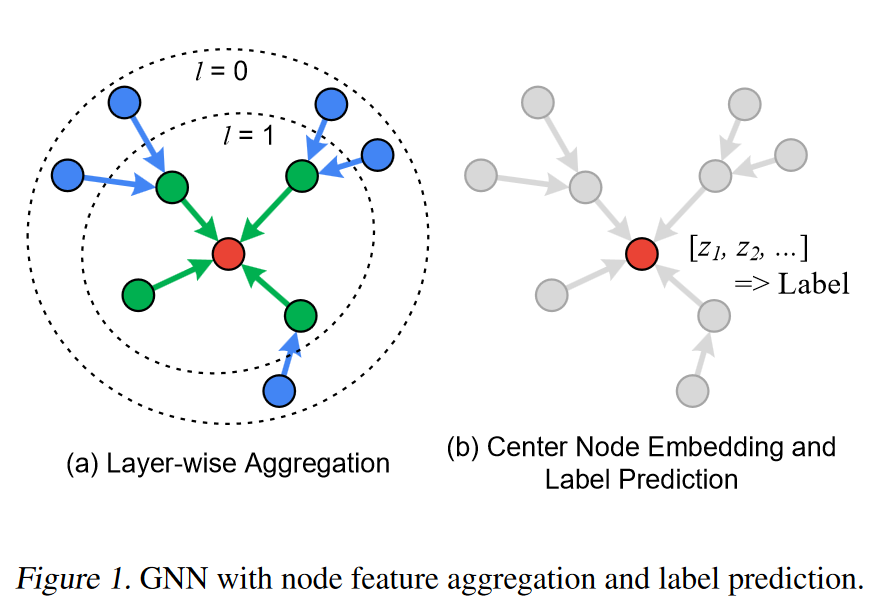
聚合与更新
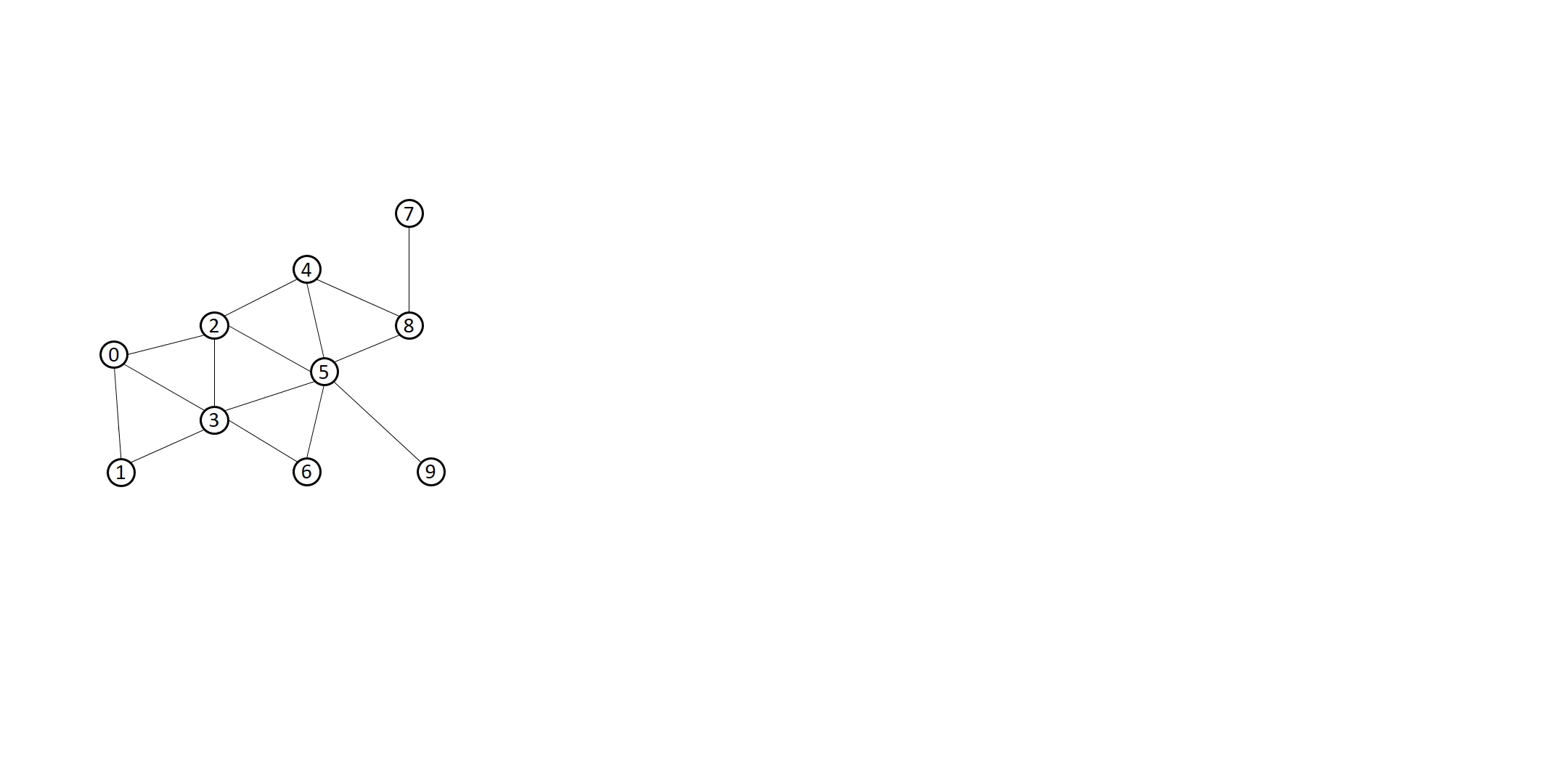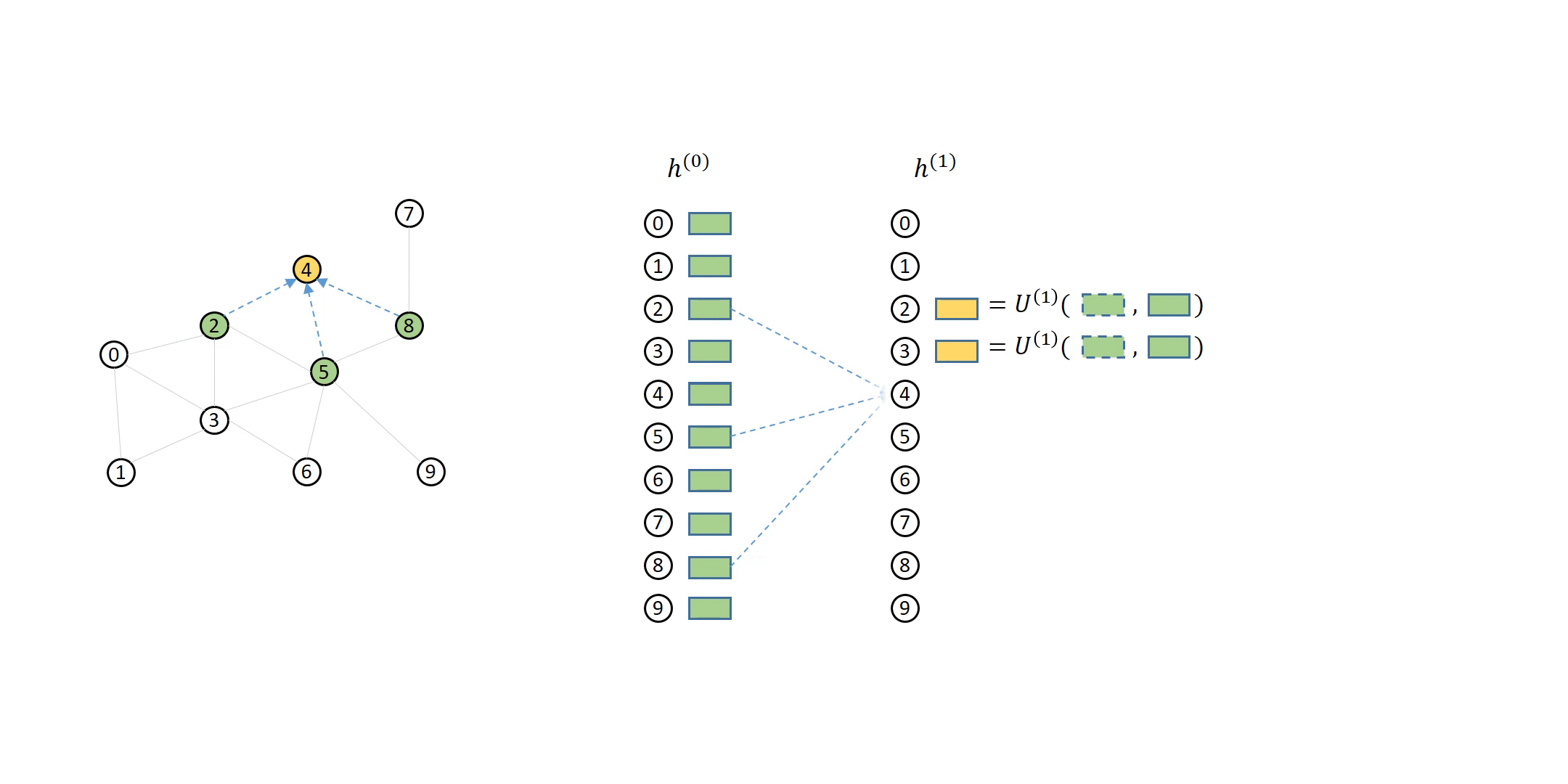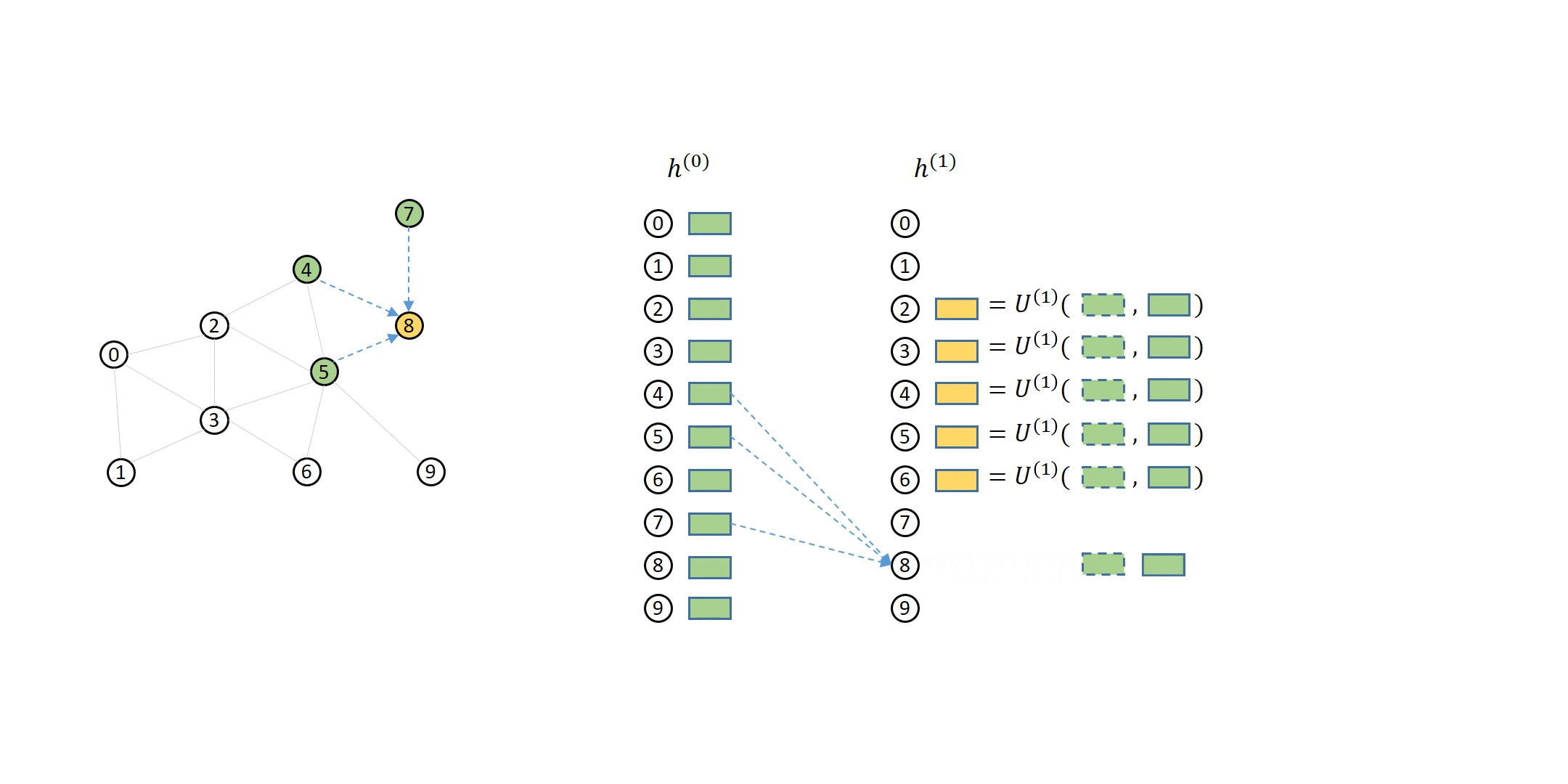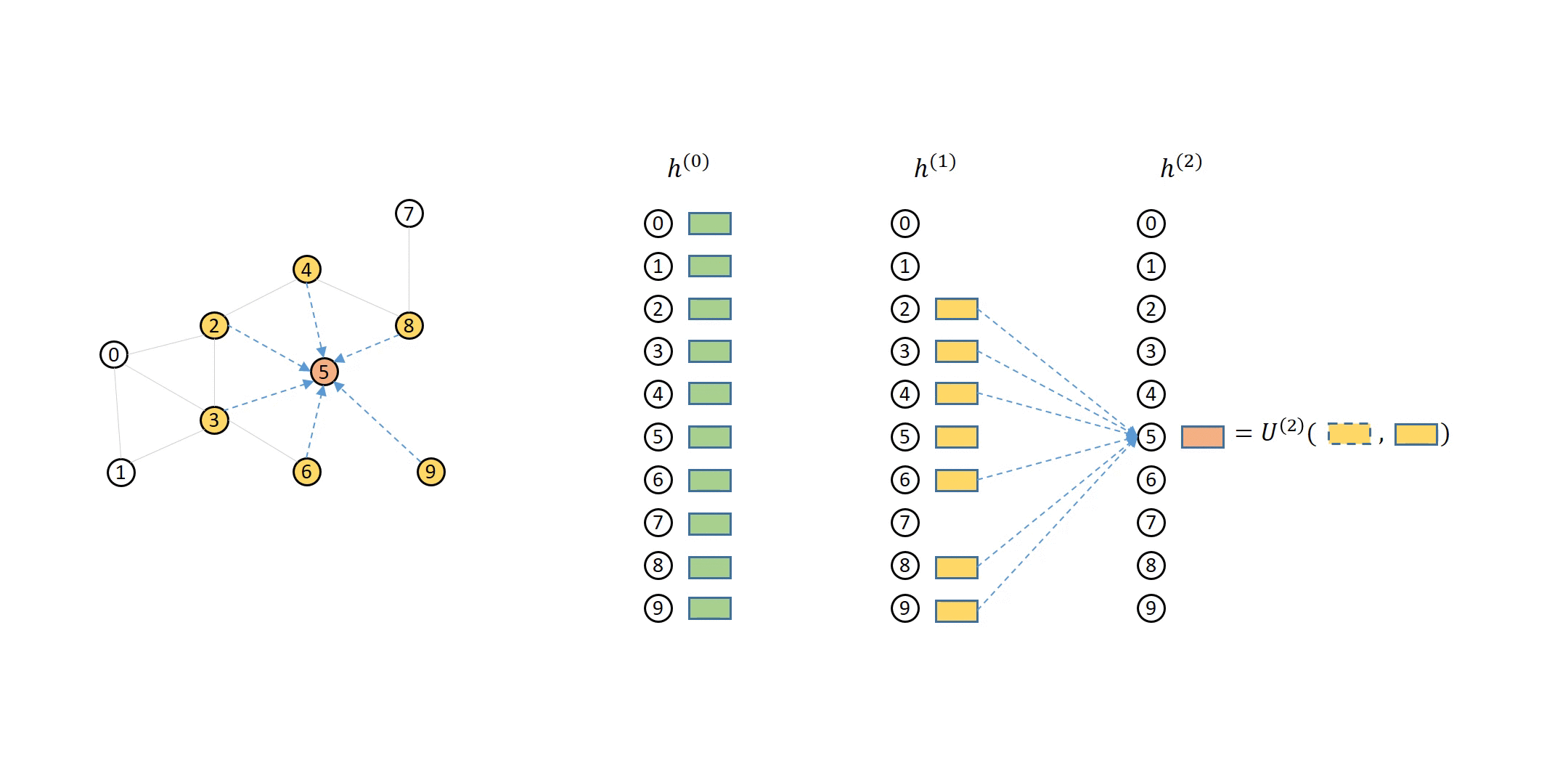
假设我们有一个 3 层的 GNN 模型,那么采样的顺序是从第 3 层到第 1 层,而聚合的顺序是从第一层到第三层。节点用自身特征和聚合的邻居特征重新生成下一层中的表示。每层的源节点和目标节点可以用一个二分图来表示。
DGL 中 Feature Collection 的实现
DGL 支持预取机制,可以在对特征矩阵进行切片时隐式地将特征自动传送到设备内存中。
GNN 中的并行训练
在深度学习模型的并行训练中,有几种常见的策略,如数据并行、模型并行、流水线并行和混合并行等。
数据并行
每个 GPU 上都拥有完整的模型,将数据拆分后传送给不同的 GPU 训练。在反向传播阶段,多个 GPU 之间要通过 AllReduce 同步梯度信息。
模型并行
每个 GPU 上都拥有完整的数据,将模型拆分到不同的 GPU。省略了梯度同步的开销,但也带来了数据在多个 GPU 广播的通信开销。
流水线并行
当模型很大层数很多,在设备内存中无法存放的时候,可以将网络中的层划分为不同的阶段,每个 GPU 值负责计算其中的一个阶段,上一阶段的输出作为下一阶段的输入。
混合并行
上述几种策略可以同时使用,以 GPT-3 的并行训练策略为例,它首先被分为 64 个阶段,进行流水并行,每个阶段都运行在 6 台 DGX-A100 主机上。在 6 台主机之间,进行的是数据并行训练;每台主机有 8 张 GPU 显卡,同一台机器上的 8 张 GPU 显卡之间是进行模型并行训练。
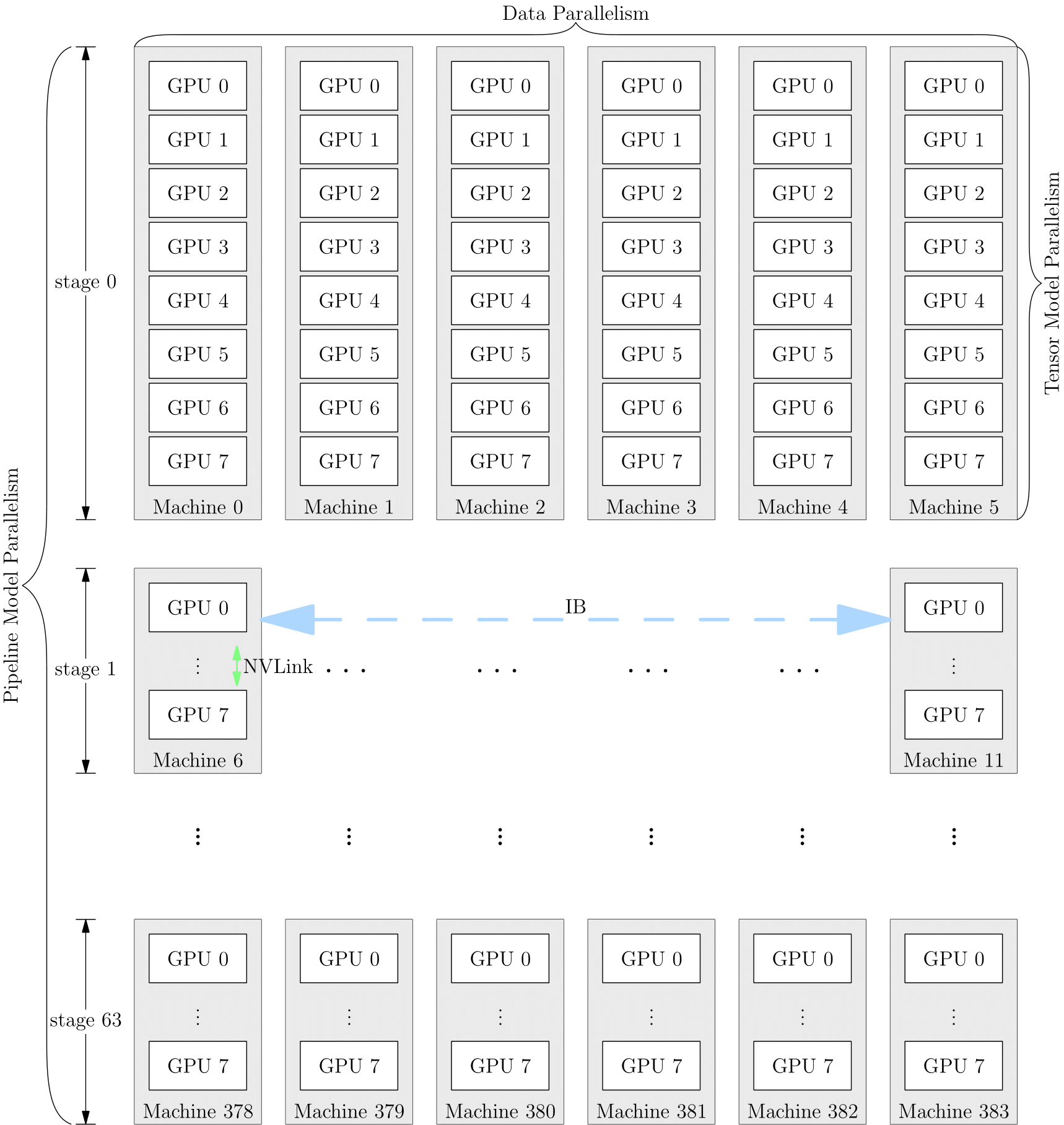
基于 Pytorch 的 DDP
DDP 全称 DistributedDataParallel,可以用于分布式并行训练和多卡并行训练,DDP 为每个 GPU 创建单独的进程,使用更高效的通信后端,如 nccl 来实现多个设备的快速模型参数同步。
具体到 GNN 中的节点分类任务的 DDP 训练,示例代码如下:
import copy
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn.functional as F
from torch import Tensor
from torch.nn.parallel import DistributedDataParallel
from tqdm import tqdm
from torch_geometric.datasets import Reddit
from torch_geometric.loader import NeighborLoader
from torch_geometric.nn import SAGEConv
class SAGE(torch.nn.Module):
def __init__(self, in_channels: int, hidden_channels: int,
out_channels: int, num_layers: int = 2):
super().__init__()
self.convs = torch.nn.ModuleList()
self.convs.append(SAGEConv(in_channels, hidden_channels))
for _ in range(num_layers - 2):
self.convs.append(SAGEConv(hidden_channels, hidden_channels))
self.convs.append(SAGEConv(hidden_channels, out_channels))
def forward(self, x: Tensor, edge_index: Tensor) -> Tensor:
for i, conv in enumerate(self.convs):
x = conv(x, edge_index)
if i < len(self.convs) - 1:
x = x.relu_()
x = F.dropout(x, p=0.5, training=self.training)
return x
@torch.no_grad()
def inference(self, x_all: Tensor, device: torch.device,
subgraph_loader: NeighborLoader) -> Tensor:
pbar = tqdm(total=len(subgraph_loader) * len(self.convs))
pbar.set_description('Evaluating')
# Compute representations of nodes layer by layer, using *all*
# available edges. This leads to faster computation in contrast to
# immediately computing the final representations of each batch:
for i, conv in enumerate(self.convs):
xs = []
for batch in subgraph_loader:
x = x_all[batch.node_id.to(x_all.device)].to(device)
x = conv(x, batch.edge_index.to(device))
x = x[:batch.batch_size]
if i < len(self.convs) - 1:
x = x.relu_()
xs.append(x.cpu())
pbar.update(1)
x_all = torch.cat(xs, dim=0)
pbar.close()
return x_all
def run(rank, world_size, dataset):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group('nccl', rank=rank, world_size=world_size)
data = dataset[0]
data = data.to(rank, 'x', 'y') # Move to device for faster feature fetch.
# Split training indices into `world_size` many chunks:
train_idx = data.train_mask.nonzero(as_tuple=False).view(-1)
train_idx = train_idx.split(train_idx.size(0) // world_size)[rank]
kwargs = dict(batch_size=1024, num_workers=4, persistent_workers=True)
train_loader = NeighborLoader(data, input_nodes=train_idx,
num_neighbors=[25, 10], shuffle=True,
drop_last=True, **kwargs)
if rank == 0: # Create single-hop evaluation neighbor loader:
subgraph_loader = NeighborLoader(copy.copy(data), num_neighbors=[-1],
shuffle=False, **kwargs)
# No need to maintain these features during evaluation:
del subgraph_loader.data.x, subgraph_loader.data.y
# Add global node index information:
subgraph_loader.data.node_id = torch.arange(data.num_nodes)
torch.manual_seed(12345)
model = SAGE(dataset.num_features, 256, dataset.num_classes).to(rank)
model = DistributedDataParallel(model, device_ids=[rank])
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(1, 21):
model.train()
for batch in train_loader:
optimizer.zero_grad()
out = model(batch.x, batch.edge_index.to(rank))[:batch.batch_size]
loss = F.cross_entropy(out, batch.y[:batch.batch_size])
loss.backward()
optimizer.step()
dist.barrier()
if rank == 0:
print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}')
if rank == 0 and epoch % 5 == 0: # We evaluate on a single GPU for now
model.eval()
with torch.no_grad():
out = model.module.inference(data.x, rank, subgraph_loader)
res = out.argmax(dim=-1) == data.y.to(out.device)
acc1 = int(res[data.train_mask].sum()) / int(data.train_mask.sum())
acc2 = int(res[data.val_mask].sum()) / int(data.val_mask.sum())
acc3 = int(res[data.test_mask].sum()) / int(data.test_mask.sum())
print(f'Train: {acc1:.4f}, Val: {acc2:.4f}, Test: {acc3:.4f}')
dist.barrier()
dist.destroy_process_group()
if __name__ == '__main__':
dataset = Reddit('../../data/Reddit')
world_size = torch.cuda.device_count()
print('Let\'s use', world_size, 'GPUs!')
mp.spawn(run, args=(world_size, dataset), nprocs=world_size, join=True)