为什么使用GPU采样而不是CPU
在一个典型的使用GPU来加速图神经网络的系统中,每次迭代可以抽象为三个阶段,分别是采样、特征提取和模型训练。在系统初始化部分完成数据集的加载和预处理、定义Dataloader、Sampler和模型,随后开始训练,Dataloader负载加载一个minibatch,Sampler对其进行采样得到采样子图,从内存中聚合子图对应特征并通过PCIe传输至GPU内存中,GPU得到完整的数据后进行前向计算、反向传播和梯度更新,至此一次迭代完成。
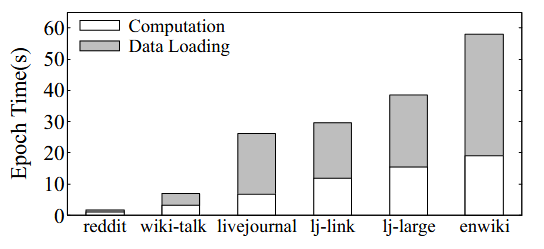
在上面的场景下,使用GPU大大加速了训练的过程,特征提取成为了系统最大的瓶颈。近年来,已经有许多研究从特征缓存和NVLink等角度出发优化PCIe上的特征流量,取得了明显的效果。
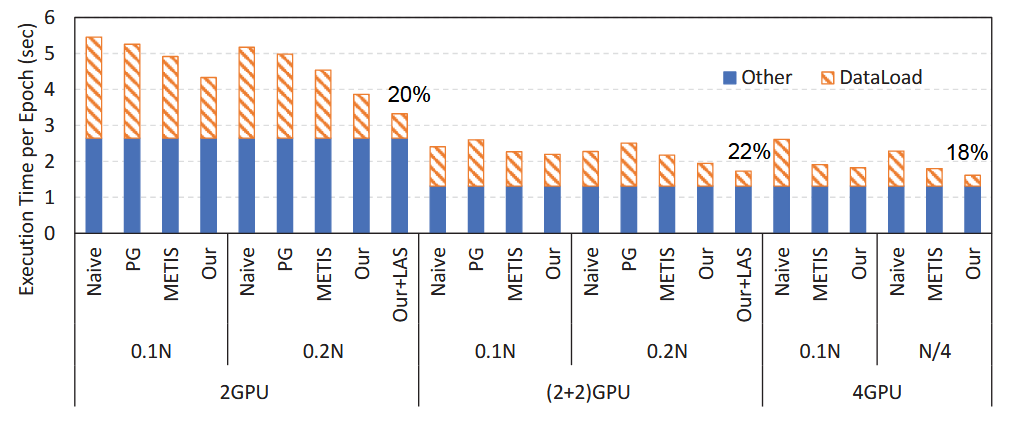
上图中Song的研究表明在对特征提取采用了各种优化手段之后,数据加载的开销在整个系统中的占比已经下降到一个较低的水平。
在GNN系统中,特征储存在CPU内存,特征提取总是由CPU完成的,此外CPU还要负责各种并发、进程切换等任务,让并行度小得可怜的CPU承担采样的任务会进一步加剧系统中对CPU资源的竞争。
使用GPU高度并行的核心来进行图采样听起来是个很不错的选择,但由于图访问的不规则性,图采样难以充分利用GPU资源,对此NextDoor通过提供一种“传输并行性”结合拓扑缓存实现了在GPU上的高速采样,DGL和Quiver等也提供了在GPU上采样的实现。相较于CPU采样,GPU采样达到了数倍的性能提升。
多GPU如何采样
DGL方案
DGL中使用单个GPU进行采样的方法很简单,只需要将图对象转移到对应的设备上,就可以使用该GPU进行采样。对于图拓扑太大以至于无法放置在GPU上的图,DGL还提供了UVA访问模式,可以将图放在CPU内存上,同时使用GPU采样,测试表明使用UVA模式要比将图放在GPU上采样慢。
然后上述设置是针对单GPU的,如果希望使用多个GPU同时采样,DGL的最佳实践推荐在CPU内存中维护一份图拓扑,为每个GPU分别设置一个采样器并通过UVA模式来访问图拓扑。这样做的好处是多个GPU可以共享一份图拓扑,没有额外的数据冗余,但是UVA模式的性能显著低于本地显存直接访问的性能。
当然我们也可以直接简单地将图复制若干份并传输到设备内存上,于是每个GPU都可以快速地访问图拓扑数据,唯一的缺点是这种方法带来了极大的数据冗余,严重浪费显存空间,一方面占据了模型训练和特征缓存的空间,另一方面损害了大图可扩展性。
GNNLab方案
使用GPU进行采样时,拓扑数据必须在设备内存中,使用GPU进行训练时也需要将一部分特征放置在设备内存中来加速训练,而采样和训练是不会在一个GPU上同时执行的,因此传统的GNN系统无法同时利用这两者带来的益处,GNNLab通过为采样和训练分配不同的专用GPU来将时间共享转换为空间共享,从而提高系统整体性能。
在GNNLab中,用于采样的GPU可以迅速切换为训练GPU,反之则不行,因为采样GPU事先就将全部的拓扑数据保存在GPU中,而训练GPU则在显存中初始化了特征缓存。当训练GPU切换为采样GPU时,需要花费大量时间来将完整的图拓扑装载到显存中,而训练GPU在每次迭代中只需要一小部分节点特征,这可以从CPU内存中获取,这个成本是我们所能接受的。
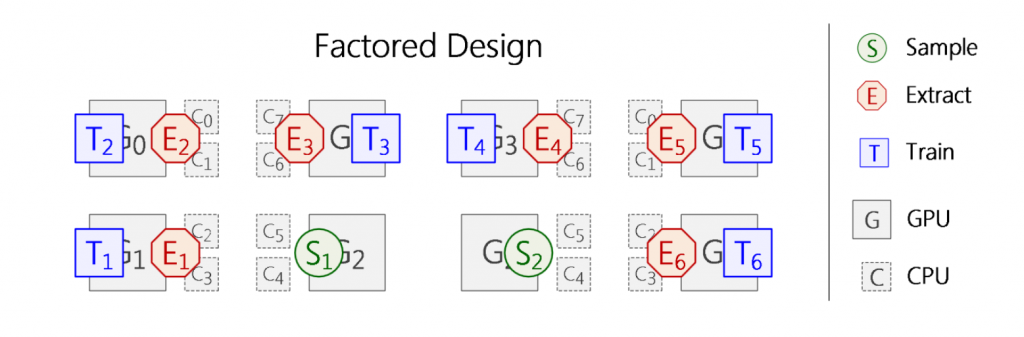
GNNLab还使用一个简单的收益指数来决定是否切换GPU的执行模式,以此来匹配采样和训练的速度差异。
这不代表它没有缺点,GNNLab同样需要在采样GPU上复制一份完整的图拓扑,存在一定的冗余,另外它没有仔细地考虑GPU资源的分配,比如特征缓存空间的大小对训练速度的影响。
采样和训练如何协调
采样和训练实际上是两个完全不同的任务,从数据流动的角度来看,采样器接收图拓扑和一个batch,生成一个采样子图,训练器接收这个子图和对应的特征进行计算。并且考虑到采样子图本身只占据很小的空间,因此我们可以将采样和训练解耦,根据它们生产消费采样子图的速度来分配计算和存储资源,从而提高资源利用率,减少训练进程的空等待。
一个简单的方法是使用异步队列来连接采样器和训练器,将生成的子图添加到队列中,训练进程每次迭代都从队列中获取一份子图进行训练。
此外,还要考虑多GPU采样带来的问题,如图拓扑的划分、缓存等,资源调度的效率、开销等。
