前言
最近打算基于Pytorch和vllm框架对一些底层模块进行定制,工欲善其事必先利其器,为了能够使用VSCode在远程服务器上丝滑地进行CUDA编程,环境搭建必不可少。
CMake为我们提供了一套完整的构建系统,只需要通过简单地配置文件就可以自由且自动地帮我们编译好模块和可执行文件,同时vscode的插件也对CMake提供了非常丰富的支持。CMake还提供了代码调式接口,允许vscode从CMake的生成目标启动调试,这为我们提供了不少便利。CMake的安装步骤参见之前的笔记。
开始配置
以下是本文的环境信息和所有需要用到的工具:
OS:Ubuntu 20.04
编辑器:VSCode
构建工具:CMake
CUDA环境:CUDAToolkit 12.4
VSCode插件:
- C/C++插件 提供C++/CUDA的语法高亮、智能补全、编译调式支持
- Cmake Tools插件 提供对CMake的配置支持和GUI支持等
- Nsight Visual Studio Code Edition 提供CUDA特定语法的高亮显示和智能补全等Hello World
接下来,让我们配置和运行一个最小的Demo。
新建项目,并按照下面的目录结构初始化。
.
├── CMakeLists.txt
├── include
│ ├── common.cuh
│ └── error.cuh
└── src
├── common.cu
└── main.cu每个文件的内容如下:
#CMakeLists.txt
cmake_minimum_required(VERSION 3.17.0) #设置cmake版本
project(CUDAStudy VERSION 0.1.0 LANGUAGES CUDA C CXX) #项目名、版本号、语言支持
find_package(CUDAToolkit REQUIRED) #引入CUDA库
set(CMAKE_CUDA_STANDARD 14)
include_directories(${PROJECT_SOURCE_DIR}/include) #设置头文件目录
add_definitions(-DUSE_DP)
add_library(common STATIC src/common.cu) #添加静态库
add_executable(CUDAStudy src/main.cu) #添加可执行文件
target_link_libraries(CUDAStudy common)
target_link_libraries(CUDAStudy CUDA::cudart) #链接到cudart库
if(CMAKE_BUILD_TYPE STREQUAL "Debug")
target_compile_options(CUDAStudy PRIVATE $<$<COMPILE_LANGUAGE:CUDA>:-G -g>) #添加调试信息
endif()
set_target_properties(CUDAStudy PROPERTIES CUDA_SEPARABLE_COMPILATION ON)
# 测试和打包功能
include(CTest)
enable_testing()
set(CPACK_PROJECT_NAME ${PROJECT_NAME})
set(CPACK_PROJECT_VERSION ${PROJECT_VERSION})
include(CPack)
//common.cuh
#pragma once
#include <stdio.h>
__global__ void hello_world();
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo);
float cuda_malloc_test(int size, bool up);
float cuda_host_malloc_test(int size, bool up);
error.cuh
#pragma once
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
//common.cu
#include "common.cuh"
__global__ void hello_world()
{
printf("Hello, World from GPU! common\n");
}
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo)
{
__shared__ unsigned int temp[256];
temp[threadIdx.x] = 0;
__syncthreads();
int i = threadIdx.x + blockIdx.x * blockDim.x;
int offset = blockDim.x * gridDim.x;
while (i < size)
{
atomicAdd(&temp[buffer[i]], 1);
i += offset;
}
__syncthreads();
atomicAdd(&(histo[threadIdx.x]), temp[threadIdx.x]);
}
float cuda_malloc_test(int size, bool up)
{
cudaEvent_t start, stop;
int *a, *dev_a;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
a = (int *)malloc(size * sizeof(*a));
cudaMalloc((void **)&dev_a, sizeof(*dev_a) * size);
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
if (up)
{
cudaMemcpy(dev_a, a, sizeof(*dev_a) * size, cudaMemcpyHostToDevice);
}
else
{
cudaMemcpy(a, dev_a, sizeof(*dev_a) * size, cudaMemcpyDeviceToHost);
}
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
free(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return elapsedTime;
}
float cuda_host_malloc_test(int size, bool up)
{
cudaEvent_t start, stop;
int *a, *dev_a;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaHostAlloc((void **)&a, size * sizeof(*a), cudaHostAllocDefault);
cudaMalloc((void **)&dev_a, sizeof(*dev_a) * size);
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
if (up)
{
cudaMemcpy(dev_a, a, sizeof(*dev_a) * size, cudaMemcpyHostToDevice);
}
else
{
cudaMemcpy(a, dev_a, sizeof(*dev_a) * size, cudaMemcpyDeviceToHost);
}
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaFreeHost(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return elapsedTime;
}//main.cu
#include "error.cuh"
#include <stdio.h>
#include "common.cuh"
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
const int NUM_REPEATS = 10;
const int TILE_DIM = 32;
const int N = 12800;
void timing(const real *d_A, real *d_B, const int N, const int task);
__global__ void copy(const real *A, real *B, const int N);
__global__ void transpose1(const real *A, real *B, const int N);
__global__ void transpose2(const real *A, real *B, const int N);
__global__ void transpose3(const real *A, real *B, const int N);
void print_matrix(const int N, const real *A);
__global__ void reduce_global(real *d_x, real *d_y);
__global__ void reduce_shared(real *d_x, real *d_y);
__global__ void transpose1_with_bank_conflict(const real *A, real *B, const int N);
__global__ void hello_world();
int main(int argc, char **argv)
{
hello_world<<<1, 1>>>();
const int N2 = N * N;
const int M = sizeof(real) * N2;
real *h_A = (real *)malloc(M);
real *h_B = (real *)malloc(M);
for (int n = 0; n < N2; ++n)
{
h_A[n] = n;
}
real *d_A, *d_B;
CHECK(cudaMalloc(&d_A, M));
CHECK(cudaMalloc(&d_B, M));
CHECK(cudaMemcpy(d_A, h_A, M, cudaMemcpyHostToDevice));
printf("\ncopy:\n");
timing(d_A, d_B, N, 0);
printf("\ntranspose with coalesced read:\n");
timing(d_A, d_B, N, 1);
printf("\ntranspose with coalesced write:\n");
timing(d_A, d_B, N, 2);
printf("\ntranspose with coalesced write and __ldg read:\n");
timing(d_A, d_B, N, 3);
CHECK(cudaMemcpy(h_B, d_B, M, cudaMemcpyDeviceToHost));
if (N <= 10)
{
printf("A =\n");
print_matrix(N, h_A);
printf("\nB =\n");
print_matrix(N, h_B);
}
free(h_A);
free(h_B);
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
return 0;
}
void timing(const real *d_A, real *d_B, const int N, const int task)
{
const int grid_size_x = (N + TILE_DIM - 1) / TILE_DIM;
const int grid_size_y = grid_size_x;
const dim3 block_size(TILE_DIM, TILE_DIM);
const dim3 grid_size(grid_size_x, grid_size_y);
float t_sum = 0;
float t2_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
switch (task)
{
case 0:
copy<<<grid_size, block_size>>>(d_A, d_B, N);
break;
case 1:
transpose1<<<grid_size, block_size>>>(d_A, d_B, N);
break;
case 2:
transpose2<<<grid_size, block_size>>>(d_A, d_B, N);
break;
case 3:
transpose3<<<grid_size, block_size>>>(d_A, d_B, N);
break;
default:
printf("Error: wrong task\n");
exit(1);
break;
}
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
if (repeat > 0)
{
t_sum += elapsed_time;
t2_sum += elapsed_time * elapsed_time;
}
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
const float t_ave = t_sum / NUM_REPEATS;
const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave);
printf("Time = %g +- %g ms.\n", t_ave, t_err);
}
__global__ void copy(const real *A, real *B, const int N)
{
const int nx = blockIdx.x * TILE_DIM + threadIdx.x;
const int ny = blockIdx.y * TILE_DIM + threadIdx.y;
const int index = ny * N + nx;
if (nx < N && ny < N)
{
B[index] = A[index];
}
}
__global__ void transpose1(const real *A, real *B, const int N)
{
const int nx = blockIdx.x * blockDim.x + threadIdx.x;
const int ny = blockIdx.y * blockDim.y + threadIdx.y;
if (nx < N && ny < N)
{
B[nx * N + ny] = A[ny * N + nx];
}
}
__global__ void transpose2(const real *A, real *B, const int N)
{
const int nx = blockIdx.x * blockDim.x + threadIdx.x;
const int ny = blockIdx.y * blockDim.y + threadIdx.y;
if (nx < N && ny < N)
{
B[ny * N + nx] = A[nx * N + ny];
}
}
__global__ void transpose3(const real *A, real *B, const int N)
{
const int nx = blockIdx.x * blockDim.x + threadIdx.x;
const int ny = blockIdx.y * blockDim.y + threadIdx.y;
if (nx < N && ny < N)
{
B[ny * N + nx] = __ldg(&A[nx * N + ny]);
}
}
void print_matrix(const int N, const real *A)
{
for (int ny = 0; ny < N; ny++)
{
for (int nx = 0; nx < N; nx++)
{
printf("%g\t", A[ny * N + nx]);
}
printf("\n");
}
}
__global__ void reduce_global(real *d_x, real *d_y)
{
const int tid = threadIdx.x;
real *x = d_x + blockIdx.x * blockDim.x;
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1)
{
x[tid] += x[tid + offset];
}
__syncthreads();
if (tid == 0)
{
d_y[blockIdx.x] = x[0];
}
}
__global__ void reduce_shared(real *d_x, real *d_y)
{
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
__shared__ real s_y[128];
s_y[tid] = (n < N) ? d_x[n] : 0;
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1)
{
if (tid < offset)
{
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
if (tid == 0)
{
d_y[bid] = s_y[0];
}
}
__global__ void transpose1_with_bank_conflict(const real *A, real *B, const int N)
{
__shared__ real S[TILE_DIM][TILE_DIM];
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
int nx1 = bx + threadIdx.x;
int ny1 = by + threadIdx.y;
if (nx1 < N && ny1 < N)
{
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
if (nx2 < N && ny2 < N)
{
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
}
以上就是代码的全部内容,此时无需其他任何配置就可以使用CMake完成可执行程序的构建,编译好的可执行文件默认在项目根目录下的build文件夹中。
点击VSCode中CMake面板的生成按钮来构建可执行文件
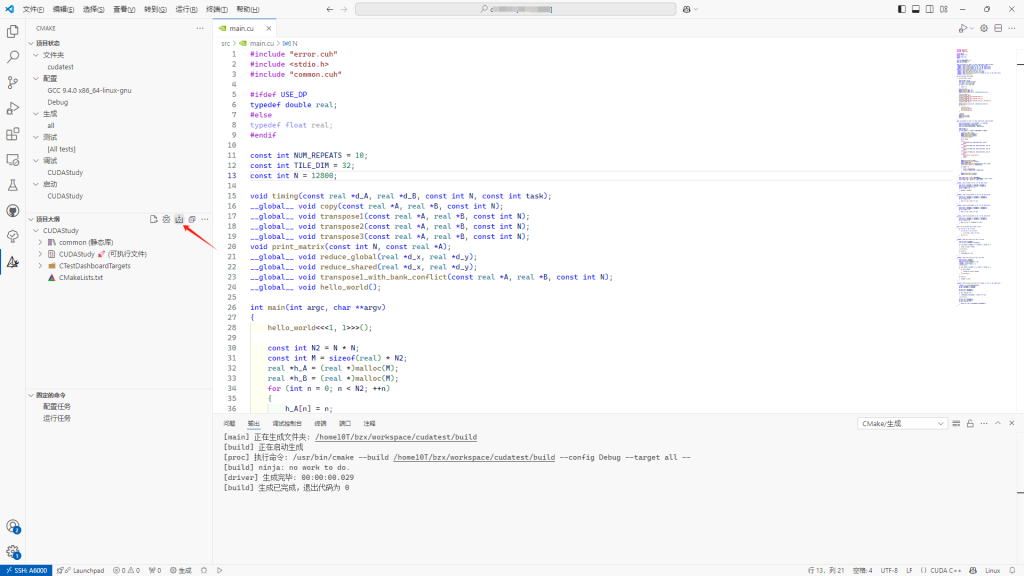
观察输出面板中的信息,没有报错,生成成功。然后进入build目录下即可看到编译好的CUDAStudy可执行文件
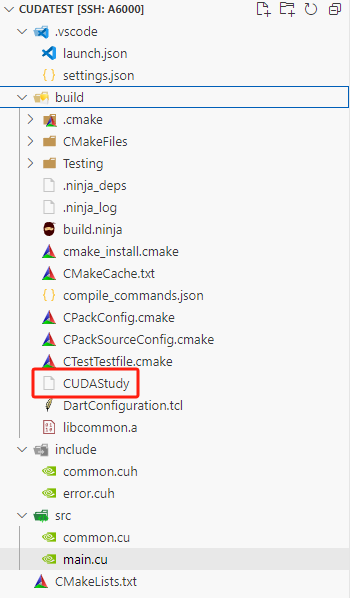
在终端中进入build目录后,执行./CUDAStudy即可运行该程序,输出如下:
❯ cd build
❯ ls
build.ninja CMakeFiles compile_commands.json CPackSourceConfig.cmake CUDAStudy libcommon.a
CMakeCache.txt cmake_install.cmake CPackConfig.cmake CTestTestfile.cmake DartConfiguration.tcl Testing
❯ ./CUDAStudy
Hello, World from GPU! common
copy:
Time = 22.2461 ms.
Time = 4.00077 ms.
Time = 3.99872 ms.
Time = 3.99974 ms.
Time = 3.9977 ms.
Time = 3.9977 ms.
Time = 3.99872 ms.
Time = 3.99974 ms.
Time = 4.02637 ms.
Time = 4.02534 ms.
Time = 4.02842 ms.
Time = 4.00732 +- 0.0128075 ms.
transpose with coalesced read:
Time = 8.34352 ms.
Time = 8.39373 ms.
Time = 8.3927 ms.
Time = 8.43469 ms.
Time = 8.47053 ms.
Time = 8.48896 ms.
Time = 8.53824 ms.
Time = 8.54016 ms.
Time = 8.53811 ms.
Time = 8.54118 ms.
Time = 8.53802 ms.
Time = 8.48763 +- 0.0585286 ms.
transpose with coalesced write:
Time = 5.39853 ms.
Time = 5.38829 ms.
Time = 5.38726 ms.
Time = 5.38611 ms.
Time = 5.38726 ms.
Time = 5.38624 ms.
Time = 5.40467 ms.
Time = 5.41798 ms.
Time = 5.42208 ms.
Time = 5.41901 ms.
Time = 5.41901 ms.
Time = 5.40179 +- 0.0155024 ms.
transpose with coalesced write and __ldg read:
Time = 5.80416 ms.
Time = 5.78054 ms.
Time = 5.78262 ms.
Time = 5.78048 ms.
Time = 5.78355 ms.
Time = 5.78253 ms.
Time = 5.78253 ms.
Time = 5.7856 ms.
Time = 5.78458 ms.
Time = 5.78458 ms.
Time = 5.78243 ms.
Time = 5.78294 +- 0.00195312 ms.此时也可按Ctrl Shift+P选择CMake:Debug进行调试,但是无法在CUDA代码行添加断点,调试过程中执行到CUDA代码也会自动跳过,这是因为CMake的默认调试器是GDB,GDB是无法调试CUDA代码的,我们应该使用cuda-gdb。
这里有多种配置方式,接下来将逐一介绍
CMake Debug
CMake提供了调试入口,可以自动识别调试目标和位置,只需要将其调试器设置为cuda-gdb即可
在项目根目录下创建.vscode文件夹,其下创建settings.json,添加如下内容:
//setting.json
{
"cmake.debugConfig": {
"miDebuggerPath": "/usr/local/cuda-12.3/bin/cuda-gdb"
},
}现在使用CMake:Debug就可以调试核函数了,快捷键为Shift+F5。
如果你需要对调试添加更细致的配置,那么就需要创建launch.json了(也可以在settings.json中的cmake.debugConfig下添加启动参数等配置),对应两种方式,一种基于Nsight Visual Studio Code Edition,调试类型为cuda-gdb,需要在运行和调试面板中启动,另一种基于C/C++,调式类型为cppdbg,VSCode中右上角的运行/调试按钮会调用该配置文件。
Nsight Debug
//launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "CUDA C++: Launch",
"type": "cuda-gdb",
"request": "launch",
"program": "${command:cmake.launchTargetPath}",
"cwd": "${workspaceFolder}"
},
{
"name": "CUDA C++: Attach",
"type": "cuda-gdb",
"request": "attach"
}
]
}点击调式面板中的按钮进行调试即可,如下图:
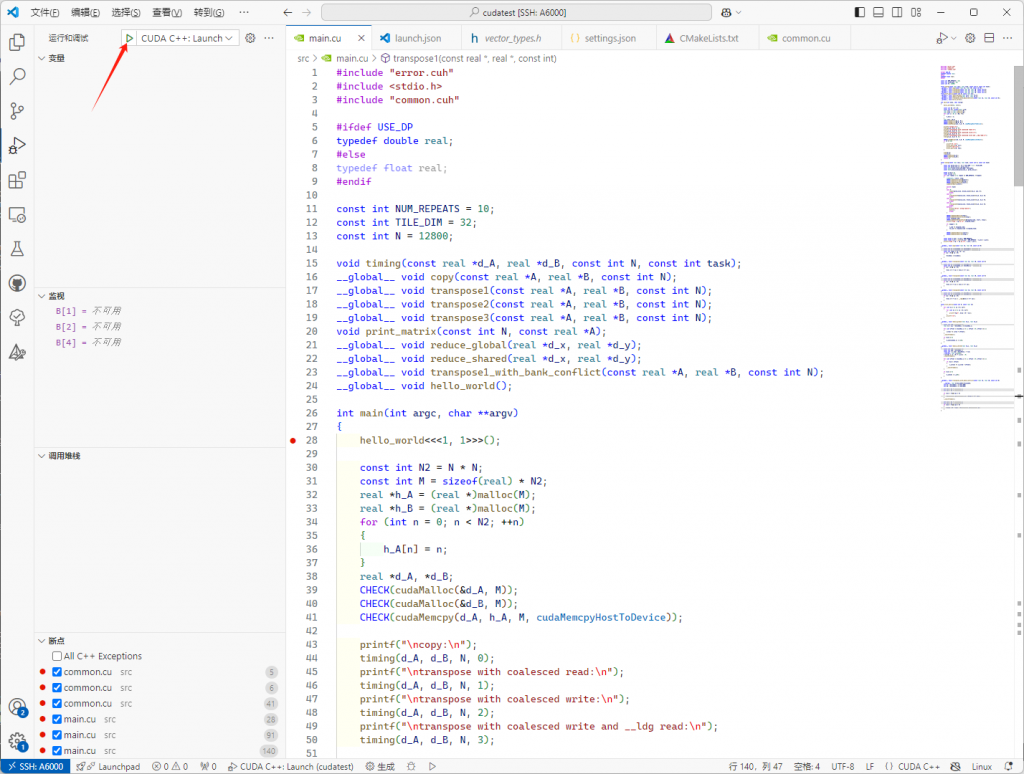
C/C++ Debug
使用gdb作为调试器,并将miDebugger设置为cuda-gdb。
//launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "CUDA Debug",
"type": "cppdbg",
"request": "launch",
"program": "${command:cmake.launchTargetPath}", // CMake 生成的目标路径
"args": [], // 运行时参数
"stopAtEntry": false,
"cwd": "${workspaceFolder}", // 项目目录
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "/usr/local/cuda/bin/cuda-gdb", // 指定 cuda-gdb 路径
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
}
]
}此时可以选择点击编辑界面右上角的调式按钮启动调试,快捷键为F5。
注意
- 如果使用方法1和方法2无法调式核函数,可以尝试卸载相关VSCode插件并重新安装
- 如果使用方法3无法调试核函数,建议使用方法1和方法2
- 以上所有操作的前提是正确安装了CUDAToolkit,并且
cuda-gdb可以正常使用
