DeepSeek 最新论文 《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》 代码解读 仓库连接如下:deepseek-ai/Engram GitHubdeepseek-ai/Engram DeepSeek 新作…
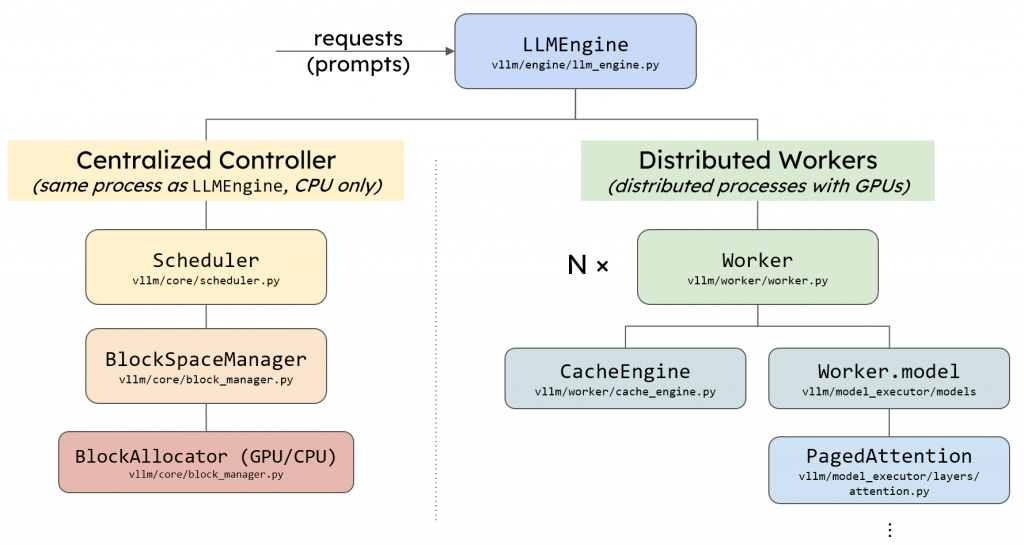
vllm中的llm_engine主要由两个模块构成,Scheduler和Executor,其中Executor负责管理并行推理时的多个设备、模型的推理计算和KV Cache的显存分配和管理,而Scheduler负责请求的调度。接下来,我将详细介绍vllm的Scheduler模块和其调度策略。 vllm模块架构 前置知识 llm是自回归的模型,在一个…

随着深度学习的层数越来越多,模型的参数也呈现出了快速增长的趋势,然而GPU内存的增长速度却远慢于模型体积的增长。有限的GPU内存限制了我们训练和部署模型的灵活性,GPU内存墙成为了现在亟待解决的问题。先前已经有许多研究进行了探索,可以概括为两大类:一是基于多级存储构建透明的数据分页和迁移机制,利用page fault在多级存储中交换数据,并对上层应…
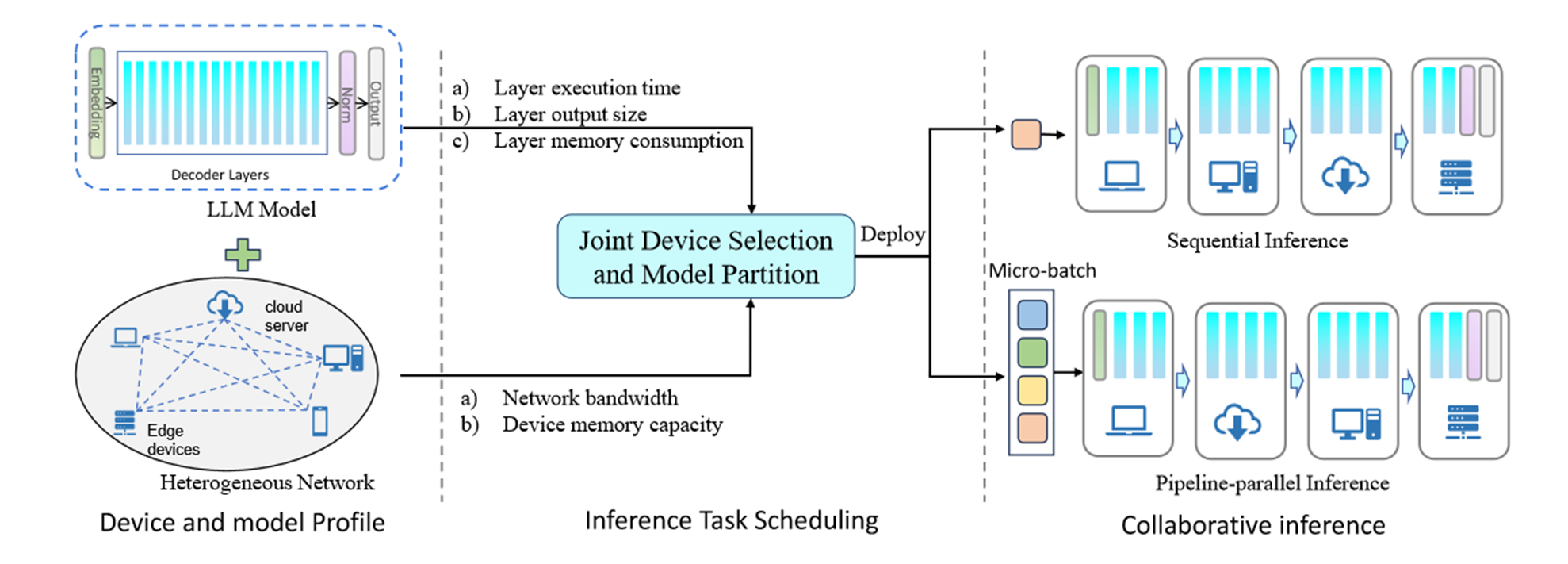
边缘计算有望通过在更靠近数据源的边缘设备上部署LLM来解决这些问题。一些工作试图利用模型量化来减小模型大小以适应资源约束的边缘设备,但这会导致精度损失。其他作品使用云边缘协作,遭受网络连接不稳定的困扰。在这项工作中,我们利用协作边缘计算来促进边缘设备和云服务器之间的协作,以共同执行高效的LLM推理。我们提出了一个通用框架,将LLM模型划分为分片并部署在分布式设备上。